基于神經網絡的混凝投藥系統預測模型
白樺, 李圭白
(哈爾濱工業大學市政環境工程學院, 黑龍江哈爾濱 150090)
摘 要:對目前水廠實際運行過程中混凝劑投量的確定及影響因素進行了分析,通過引入神經網絡預測理論建立了混凝劑投量的預測模型,并以某水廠的實際運行數據對該模型的性能進行了驗證。結果表明,網絡預測模型具有很強的自學習性、自適應性和容錯性,通過網絡的在線自學習,可使預測結果的準確度明顯提高。利用該模型可實現混凝劑投量的在線預測控制,為實現混凝劑的最優投加提供了一條有效途徑。?
關鍵詞:混凝投藥 神經網絡;預測模型;優化?
中圖分類號:TU991.22
文獻標識碼:C
文章編號:1000-4602(2002)06-0046-02
對混凝劑用量實施預測控制的關鍵是如何建立系統的預測模型。一種建模方法是基于系統的物理化學反應關系。由于混凝過程是一個復雜的物理化學反應過程,目前還很難通過對其反應機理的研究來準確地建立反應過程的數學模型;另一種建模方法是根據系統的輸入/出特性(數據) 建模。由于傳統的數學模型(基于系統輸入/出數據采用多元線性回歸方式建立)[2]自身不具備容錯性和自學習性而大大限制了其應用。由此,筆者提出一種基于人工神經網絡、具有很強的容錯性和自學習、自適應能力的方法,這種方法將推進混凝投藥智能化自動控制系統的研究。
1 神經網絡預測模型的建立
1.1 混凝投藥過程的特點 ?
水處理流程一般包括凝聚、絮凝、沉淀、過濾4個階段。其中混凝過程是主要環節,直接關系到出水的水質,而在這一過程中混凝劑的投量又是一個決定性因素,要求其能夠根據原水水質參數的變化而不斷改變藥劑量以滿足出水水質的要求。分析混凝劑投加后的化學反應過程得出,濁度、pH值、TOC或CODMn、色度、溫度、流量等幾個主要原水參數將影響混凝劑的投量和混凝效果[1]。對于大多數水廠,混凝的控制指標大都以出水濁度衡量。
1.2 預測模型
預測模型結構見圖1。
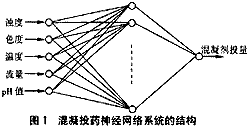
找出影響混凝效果的主要因素之后可以建立系統輸入參數—影響混凝投藥效果的主要因素與系統輸出參數—混凝劑投量之間的神經網絡模型。考慮到參數的在線可連續測量性,初步選取輸入層節點數為5個,分別為原水濁度、pH值、色度、溫度、流量;輸出層節點數為1個(混凝劑的投量)。隱層節點數和層數可根據神經網絡計算理論中的有關公式通過試驗確定,輸入層參數的選取可根據水源參數的具體特征修改。依據此網絡結構可實現當已知原水狀況時預測混凝劑的投量,預測值的準確程度取決于選取訓練樣本的準確性與樣本數據的代表性和全面性。?
2 實例分析
依據上述的混凝投藥神經網絡結構和BP網絡算法流程,對某處理水量為22.5×104m3/d 的水廠進行了投藥量預測。該水廠以松花江水為水源,地處哈爾濱段,水廠實際運行采用定時燒杯試驗的方法確定投藥量。
樣本數據選擇的全面性與豐富性直接關系到網絡的自學習性能,對于一定的水域,各年的水質狀況存在一定的差別,為此選取1997年、1998年的實際運行數據作為網絡的訓練樣本,分別對1999年的3月、7月的投藥量進行預測;同時為體現網絡的自學習性、自適應性及網絡對不同年份水質的適應性,分別將1999年的1月、2月數據和1月~6月數據添加到網絡的學習樣本數據中,分別對網絡進行訓練,再用訓練好的網絡分別對3月、7月的投藥量進行預測,測試結果見圖2~5。
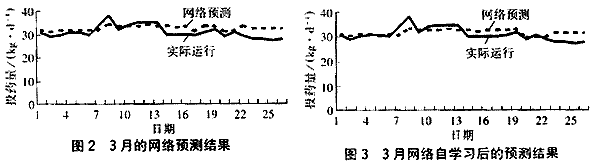
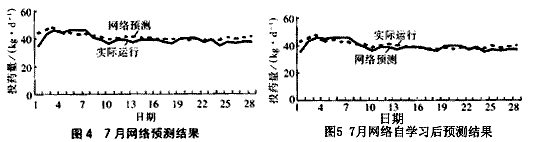
從圖2~5中可以看出,由于各年的水質存在差異,單純以1997、1998年數據作為訓練樣本 建立的網絡對1999年的3月、7月的運行狀況進行預測的結果存在較大偏差,但以1999年1月、2月和1月~6月數據添入訓練樣本建立的網絡對1999年的3月、7月的運行狀況進行預測的準確度提高,且隨著樣本數據的增加,網絡預測的平均相對誤差減小,準確度明顯提高,自學習性能顯著(見表1)。準確度是預測結果中可靠數據占總體數據的程度,反映了網絡預測結果的可信度,是網絡性能的一個衡量指標[3]。
3 結論
利用所建立的混凝投藥系統神經網絡預測模型對某水廠的實際運行數據進行預測,取得了較為滿意的結果。特別是隨著水廠實際運行數據的不斷增加,并將新數據添入訓練樣本數據中,可大大提高網絡的學習性能。由此得出,基于神經網絡的混凝投藥系統預測模型具有較強的自學習、自適應性,可在此基礎上實現前饋神經網絡預測控制以實現混凝劑的最優投加。
參考文獻:
[1]Collins Anthony G,Ellis Glenn W.Information processing coupled with expert syste ms for water treatment plants[J].ISA Transactions,1992,31(1):61-72.
[2]于東江.水廠最佳投礬劑量的確定[J].給水排水.1992,18(5):41-42.
[3]趙振宇,徐用懋.模糊理論和神經網絡的基礎與應用[M].北京:清華大學出版社,1997.
電 話:(0451)6282175 6323815
E-mail:bh70@sina.com
收稿日期:2001-10-11
論文搜索
月熱點論文
論文投稿
很多時候您的文章總是無緣變成鉛字。研究做到關鍵時,試驗有了起色時,是不是想和同行探討一下,工作中有了心得,您是不是很想與人分享,那么不要只是默默工作了,寫下來吧!投稿時,請以附件形式發至 paper@h2o-china.com ,請注明論文投稿。一旦采用,我們會為您增加100枚金幣。



